
This blog is written by guest authors Robin de Silva Jayasinghe, Thomas Pötzsch, and Joachim Mathes. Robin de Silva Jayasinghe, is a Sr. software engineer based in Germany working at synyx GmbH & Co. KG. synyx is an agile software provider in Karlsruhe, Germany that works together with different companies to find the best possible IT-solutions for their challenges. Thomas and Joachim are working as software and systems engineers at Contargo, one of the leading container hinterland logistics in Europe.
We are currently performing a shift from a classic VM based environment to a cloud-native setup, consisting of multiple Kubernetes clusters and more modern architecture and development setups.
At the end of last year, some colleagues from synyx and our long-term partner Contargo formed a new team to build an application from scratch-- an application for the collection and management of booking data for container logistics (think shipping containers).
The motivation for the application is to supersede several legacy booking applications and to provide better UX, performance, and maintainability. The new application will enable internal and external customers to integrate via user interfaces and APIs.
As we were starting a so-called "green field"-project that would need to integrate with our cloud-native setup, we focused on using well-known setups and tools in a modern fashion to further drive our DevOps-oriented development process. In retrospect, this allowed us to reap the fruits of modern development setups and processes while maintaining velocity by not overwhelming developers.
Delaying the Persistence Layer Decision
A common approach is to set up a persistence layer on the first day of the project, which can lead to feature development being slowed down by the consideration of the database and its integration. Further, it can result in opinionated decision-making if features are bound to database changes/rely on (mostly relational) database structures.
Thus, in this project, we chose to postpone all database-related decisions. Instead, we waited for a point in time where we had a thorough understanding of the domain, the underlying model, and the use cases of the application.
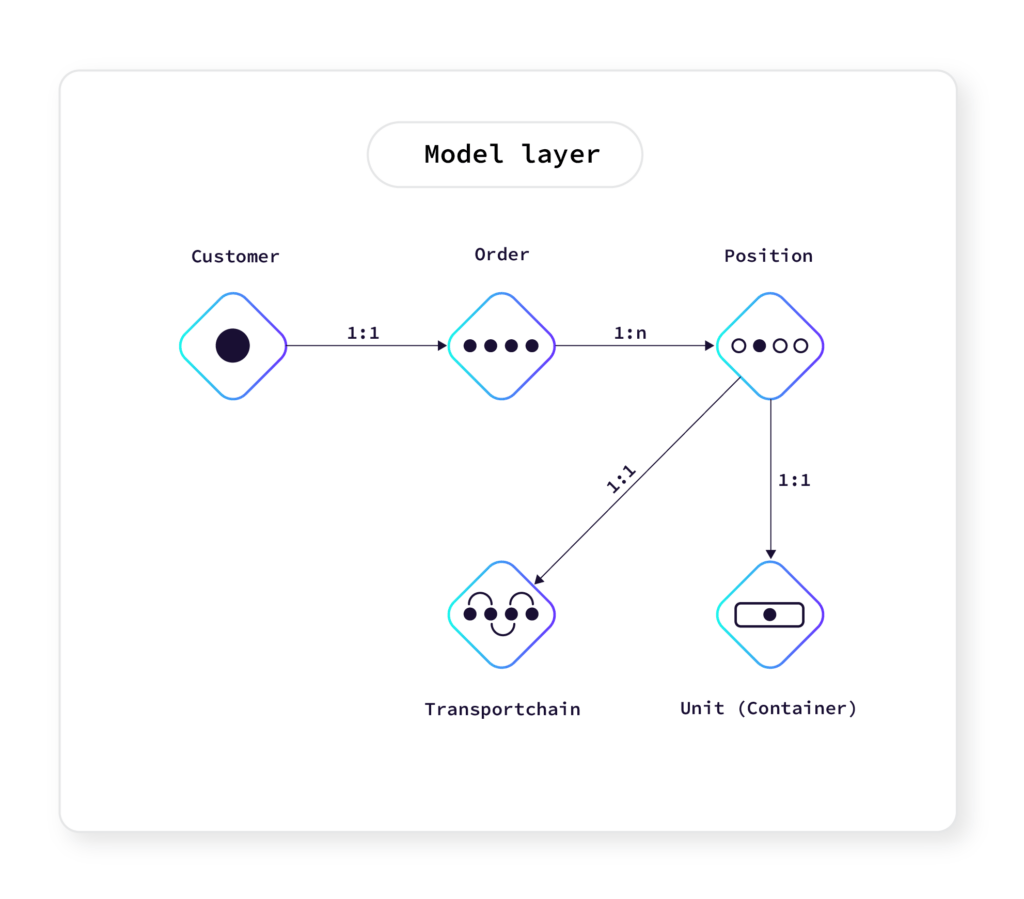
How to Implement Persistence
Inevitably, we had to start persisting our data -- which meant we needed to form a concept for our persistence layer. First, we had to decide what type of database would fit our solution. Possible options were:
- a NoSQL document store
- a graph database
- a relational database
We picked the relational approach for the following reasons:
- We had a good feeling that the domain model had stabilized and we could build a relational schema from that knowledge. Due to the perceived stabilization, we deemed the risk of major changes in our data structures to be considerably low.
- The system would perform concurrent write transactions on the entries in the database and the ACID consistency model of a relational database would help us with achieving consistency among concurrent actors in the system.
- Our team is very familiar with using relational databases in combination with Spring Boot and Spring Data JPA.
As a next step we had to choose the concrete relational database system. There were three requirements that needed to be satisfied by the potential database system:
- Cloud native: As already mentioned in the introduction, we needed a database that could run smoothly in a (private) cloud scenario. Thus, builtin support for cloud-native monitoring, alerting and distributed logging was an important factor.
- Scalability: Providing high-availability was a strong requirement for our application. Furthermore, the need for horizontal scaling due to high load was on the mid-term schedule. We knew that especially with API use cases but also with seasonal load there would be a need for horizontal scaling without additional operational effort.
- Schema flexibility: Although a good amount of our domain had been modeled and regarded as stable, we required a certain flexibility in the approach to data storage. This would allow us to be prepared for potential changes: There still were parts of the domain where we were not totally sure of the semantics or where we had document-like structure that we did not need or want to put in a relational schema. Support for key/value storage while maintaining high consistency would help to fulfill these requirements.
In contrast to MariaDB and PostgreSQL, CockroachDB excels in all three sections.
- Good support for monitoring, alerting and logging allows for seamless integration in a cloud scenario, severely simplifying the management and surveillance of nodes and clusters.
- As we experienced in another project, CockroachDB offers multiple built-in features that allow scaling by adding and removing nodes with zero downtime. This can be achieved with other databases like MariaDB or MySQL but requires additional products like Galera Cluster or Percona that come at their own cost and add complexity.
- The flexibility of schemas is guaranteed when working with CockroachDB, as CockroachDB's storage engine RocksDB is a key/value store mapping strings to strings (CockroachDB just started using a new storage engine called Pebble that was inspired by RocksDB). The technical boundaries to implement simple key/value use cases on top of that are low to non-existent. Additionally, CockroachDB, just like PostgreSQL, has support for the JSONB datatype. Thus, JSON values can not only be stored but also used for filtering expressions or in a SQL result list.
*CockroachDB scored in all 3 sections and we prepared to continue the applications development.
Hello CockroachDB!
After deciding to use CockroachDB we started a new branch of our application. First of all, we needed a CockroachDB cluster for our developer machines. Docker-compose is a very handy tool for launching up dependencies during application development:
version: "3"
services:
db-management:
# this instance exposes the management UI and other instances use it to join the cluster
image: cockroachdb/cockroach:v20.1.0
command: start --insecure --advertise-addr=db-management
volumes:
- /cockroach/cockroach-data
expose:
- "8080"
- "26257"
ports:
- "26257:26257"
- "8180:8080"
healthcheck:
test: ["CMD", "/cockroach/cockroach", "node", "status", "--insecure"]
interval: 5s
timeout: 5s
retries: 5
db-node-1:
image: cockroachdb/cockroach:v20.1.0
command: start --insecure --join=db-management --advertise-addr=db-node-1
volumes:
- /cockroach/cockroach-data
depends_on:
- db-management
db-node-2:
image: cockroachdb/cockroach:v20.1.0
command: start --insecure --join=db-management --advertise-addr=db-node-2
volumes:
- /cockroach/cockroach-data
depends_on:
- db-management
db-init:
image: cockroachdb/cockroach:v20.1.0
volumes:
- ./scripts/init-cockroachdb.sh:/init.sh
entrypoint: "/bin/bash"
command: "/init.sh"
depends_on:
- db-management
The setup describes four containers:
- db-management the database node exposing the Cockroach DB admin console and acting as the initial join-node for the other nodes.
- db-node-1, db-node-2 further database nodes joining the initial node. Can be extended with more nores like db-node-3, db-node-4, ...
- db-init is a one-shot container running a shell script that creates the inital schema and user with the cockroach CLI tool.
After we had the correct docker-compose definition we distributed the setup to our developer machines. Starting the DB cluster with docker-compose was just a matter of downloading the docker images. :)
Creating the Tables
Once the database was up we were ready to design the tables needed for our application. In our previous Spring Boot projects we created with a Liquibase - a pretty popular tool for table lifecycle management. Flyway would have been an alternative but we preferred Liquibase as we had a good amount of experience with that tool.
(Heads up: As of now, only Flyway is officially supported by CockroachDB.)
Using the existing domain model as an orientation we created roughly 50 tables and 1 sequence.
Database access from Java
One big selling point of CockroachDB is the compatibility with PostgreSQL. So, any tool that runs on PostgreSQL should be able to run on CockroachDB, too. Technically, CockroachDB speaks the PostgreSQL wire-protocol and covers it's SQL dialect. Consequently, we configured our Spring Boot application to use the PostgreSQL JDBC driver:
Added the dependency to the build descriptor (pom.xml in our case):
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
The database access is configured the application.yml:
spring:
datasource:
url: jdbc:postgresql://localhost:26257/application-schema
username: username
password: password
With this configuration in place, Spring Boot is ready to connect to the CockroachDB cluster.
Find the right data access mechanism
With the tables in place, we had to decide on the database access mechanism. Again we had several options to chose from:
- Plain JDBC / Spring JDBC template: SQL queries and result set mapping have to be implemented by the developer.
- jOOQ: jOOQ is a framework that provides API-generated DB access from the database metadata of the underlying schema.
- Spring Data JPA on top of Hibernate: JPA is the standard API for object-relational mapping (ORM). Hibernate is the most popular implementation of JPA. Spring Data adds another layer of abstraction above different data access mechanisms and makes the most common data access use-cases much easier.
- Spring Data JDBC: While following the Spring Data idioms Spring Data JDBC is more simplistic than it's JPA-based sibling. It offers some basic translation from objects into SQL statements as well as basic relationships (1:n, 1:1) between objects. It lacks, however, the caching and state-management that happens inside a JPA implementation.
Although it would have been a valid option in hindsight, we abandoned the plain JDBC solution pretty quickly. Given the number of tables and our usage of inheritance structures, the size of the potentially resulting handwritten database access code would have been huge. jOOQ would have helped a lot with generated access code and its fluent data-access APIs. However, the team had no prior experience with jOOQ, and the tight schedule of the project did not leave much space for experimenting with new APIs. In the end, we decided on the well-known JPA/Hibernate combination.
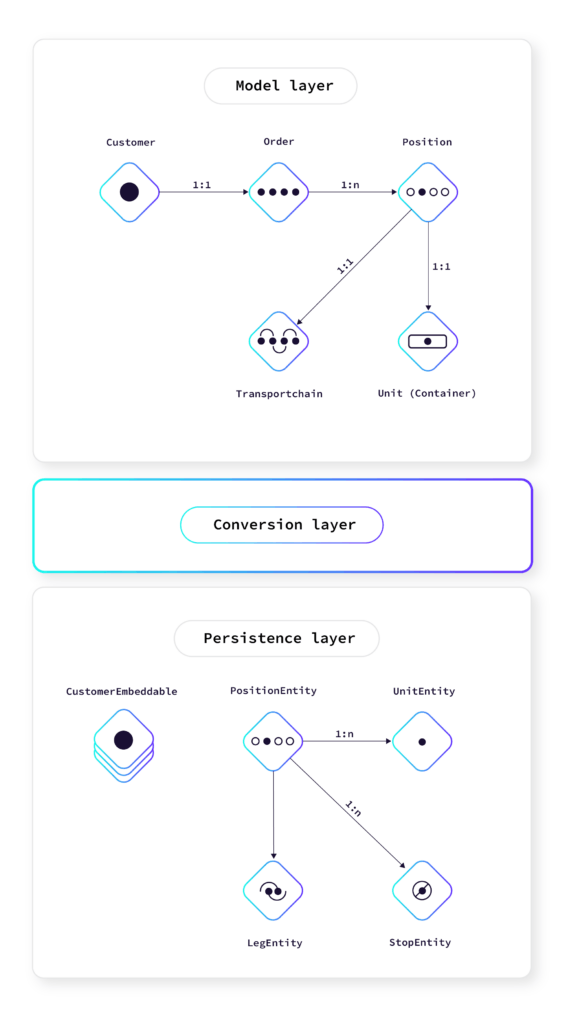
Following the DDD approach, we kept the core structures and behavior in the domain model and used the persistence part just as a data sink and source. Data coming in from the application layer is converted into the persistence structures (entities and embeddables) and saved to the database using the Spring Data repositories. Reading data works the other way around.
By using this approach we decoupled the domain model and business logic from the used persistence technology and gained a good amount of flexibility. It would have been a more traditional approach (propagated in a lot of Spring-related documentation, blogs and tutorials) to model the domain directly in JPA entities and use them in the business logic. This however limits and binds the domain model and logic to the capabilities and characteristics of JPA (or any other persistence technology).
If it turns out that JPA does not work well or if we want to extend the persistence with some aspects of CockroachDB that are not supported by JPA (e.g. key/value storage), we can easily implement them in the persistence layer without influencing the domain model.
*Note - since working on this project, and writing this blog, CockroachDB officially announced a CockroachDB dialect for Hibernate.
Optimizing Performance
After completing the schema, the JPA entities and connecting the persistence layer to the domain layer we tested the application end-2-end. While doing that we observed slow response times in certain areas of the application. We had already seen the Cockroach console UI in other projects and used it to identify the slow queries. The statement overview section of the console offers the option to activate statement diagnostics.
Once the statement was executed at least once with activated diagnostics we could download a very detailed archive containing information collected during the compilation and execution of the statement. This helped us a lot to spot table indexes that we forgot to create for some of the implicit foreign key relationships. ;)
Automatically Retry Aborted Transactions
Once we put some load on our new persistence layer we started to observe transaction errors in the application's logs. A quick search on the Internet showed that the observed errors were so called transient serialization errors. If the transaction contention cannot be resolved without serialization anomalies the conflicting transactions are aborted. This behavior is a consequence of CockroachDB's default isolation level: SERIALIZABLE.
There are different means to reduce such errors but the application code must always expect that such errors occur. For such cases it's considered best practice to implement retry logic at the client (application) side. There is a pretty detailed guide on how to do this for Spring Boot and JPA.
Although this caused some extra work and understanding for the development team, the behavior is correct and I prefer it to potentially inconsistent data in the application. JPA and Hibernate built and designed for relational databases with weaker default isolation levels. It's reasonable that some extensions needed to be done.
Automated Integration Tests
When you run integration tests you want to validate use-cases of your component without replacing its dependencies with fake implementations (e.g. mocks). For a database driven component this would mean that you have a running database at hand during your integration tests. Until like 2 years ago this was a common pattern to spin up an embedded in memory-database.
In most of the cases this was H2. As a consequence your application had to be designed in a way that it supported different database implementations. In Java a major abstraction to support different (relational) databases is JDBC. Most of the tools add an abstraction on top of JDBC to abstract from the concrete database and its SQL dialect.
It turned out, however, that abstracting from the SQL dialect does not give you a compatibility warranty. From time to time, you run into corner cases where the embedded database behaves differently from the real one and you can only detect this in the central systems.
That's why we wanted to use the same database in our integration tests as in our central systems. To achieve this, we start the database as a container along with the integration test. Testcontainrs is a fantastic tool that can be used with your test framework to manage the lifecycle of its dependent containers.
CockroachDB ran smoothly, and none of the integration tests we wrote in our persistence branch caused any issues. You have to keep a close eye on the lifecycle of your database container and the schema, however. Delete/Rebuild everything does not scale well with the number of tests. ;) Going into more details here would need a separate blog, though.
Making it DevOps
In our project there is close cooperation and a lively exchange between devs and ops. Fundamental to the further development of our platform towards a cloud-native solution is the ability of the developers to run and build applications by themselves (true to the motto: "You build it, you run it!").
Enabling developers to run their own applications has ensured that developers have been able to integrate review apps into their applications. This was a first step towards the cloud capability of the application. To do this, we enabled review apps in GitLab by configuring our pipelines and set up a dedicated namespace in our K8s cluster, where we deploy a new version for each merge request.
Parallel to the development of the persistence layer in the application, we already started to integrate CockroachDB into the review apps. For this purpose, we set up a separate CockroachDB cluster within the namespace of the review apps. Due to resource utilization, the database server is shared by all review apps for merge requests. This way, we were able to test the persistence merge request and all subsequent merge requests end to end (including the database).
During this process, CockroachDB and its community were able to convince with good, complete documentation, ready-to-use images and helm charts. The developers were thus able to work together with the ops and later alone to operate and expand the CockroachDB cluster. This included scaling, monitoring, updating and backup management of the database.
Road to Production
One of the last steps before finishing the development of persistence was to equip the currently existing stages with a CockroachDB cluster. Since our stages still exist in our classic VM environment, it was necessary to find a setup for this as well.
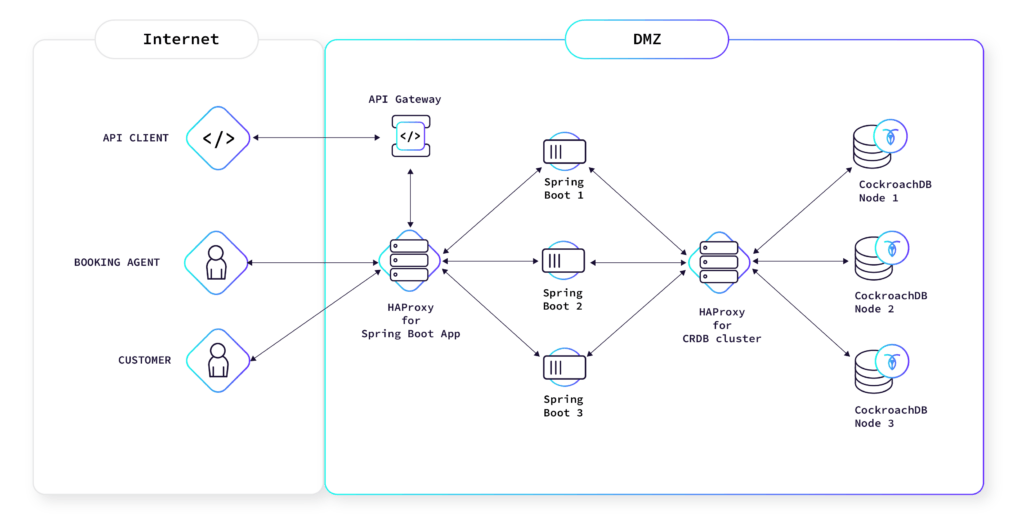
We agreed on setting up a multi-node CockroachDB cluster accompanied by an HAProxy to shuffle requests across the different nodes. After the setup was done, we prepared all application configurations with the database coordinates and credentials. Although CockroachDB-clusters typically do not reside in these habitats, it acclimatized well.
After the merge of our new persistence solution, all applications were up and running. Without bigger issues. OK, nearly without -- for the production system we used the wrong hostname, but this was corrected quickly. This was a very smooth transition for such a big (architectural) change.
Based on the experiences we made integrating CockroachDB, we expect a rather seamless migration to our cloud-native platform (K8s). The developers and ops that took part feel well enabled and confident to carry it out and drive our platform further.
Closing comments
By choosing CockroachDB as the underlying database of our new persistence layer, we made the right decision. By focusing on a cloud-native database we laid the ground stone for a modern persistence layer in our application, and departed from a conservative mindset.
Instead of introducing a well-known (possibly outdated) solution into an environment that would shift towards a cloud-native setup, we broke out of our comfort zone. We were ready to face the challenges of choosing a modern solution. And it was worth it.
Integrating CockroachDB in our developer setups was a pretty comfortable ride. Close cooperation between devs and ops made it easy to set up, operate, and use the database on a variety of platforms. CockroachDB's rich documentation and community resources helped out greatly during the process.
CockroachDB clusters are very easy to handle. We did not encounter any major issues managing them -- neither on our developer machines (Linux and MacOS) nor on our central installations with K8s and Puppet-managed virtual machines.
Thanks to the PostgreSQL compatibility we could handle CockroachDB just as if it was PostgreSQL, allowing for seamless integration with technologies we already use and know.
The platform shift to Kubernetes will take place in the near future, and we are ready to take it on with a cloud-native database. With its features, ecosystem, and flexibility, CockroachDB gives us a lot of confidence in regards to upcoming challenges.
CockroachDB is compatible with PostgreSQL via the pgwire protocol. Meaning that you could use any PostgreSQL database driver and PostgreSQL SQL dialect to access CockroachDB. However, this does not imply full compatibility since the underlying database and its behavior are not PostgreSQL. ;)
So, when you decide to use a certain tool or framework you should check with the extensive documentation before you decide. And of course, it's also a good idea to just try out the tool you want to use. Maybe it's not fully supported but good enough for your use case (like our usage of Liquibase). Nevertheless, if I had to build another relational persistence for a cloud-native application I'd definitely choose CockroachDB.

